Go1.18 sync.Map 解读
1 背景
项目中遇到了需要使用高并发的 map 的场景,众所周知 Go 官方的原生 map 是不支持并发读写的,直接并发的读写很容易触发 panic。
解决的办法有两个:
- 自己配一把锁
sync.Mutex或者更加考究一点配一把读写锁sync.RWMutex。这种方案简约直接,但是缺点也明显,就是性能不会太高。 - 使用 Go 语言在 2017 年发布的 Go 1.9 中正式加入了并发安全的字典类型
sync.Map。
很显然,方案 2 是优雅且实用的。但是,为什么官方的 sync.Map 能够在 lock free 的前提下,保证足够高的性能❓本文结合 golang 1.18 源码进行简单的分析。
2 核心思想
如果要保证并发的安全,最朴素的想法就是使用锁,但是这意味着要把一些并发的操作强制串行化,性能自然就会下降。
事实上,除了使用锁,还有一个办法也可以达到类似并发安全的目的,就是 atomic 原子操作。sync.Map 的设计非常巧妙,充分利用了 atmoic 和 mutex 互斥锁的配合。
-
read map 由于是原子包托管,主要负责高性能,但是无法保证拥有全量的 key,因为对于新增 key,会首先加到 dirty 中,所以 read 某种程度上,类似于一个 key 的快照,这个快照在某些情况下可能是全量快照。
-
dirty map 拥有全量的 key,当
Store操作要新增一个之前不存在的 key 的时候,会先增加到 dirty 中的。 -
在查找指定的 key 的时候,总会先去 read map 中寻找,并不需要锁定互斥锁。只有当 read 中没有,但 dirty 中可能会有这个 key 的时候,才会在锁的保护下去访问 dirty。
-
在存储键值对的时候,只要 read 中已存有这个 key,并且该键值对未被标记为
expunged,就会把新值存到里面并直接返回,这种情况下也不需要用到锁。 -
read 和 dirty 之间是会互相转换的,在 dirty 中查找 key 对次数足够多的时候,
sync.Map会把 dirty 直接作为 read,即触发dirty->read的转变,此时 read 中拥有全量的 key。同时在某些情况,也会出现read->dirty的转变。
3 数据结构
尽量使用原子操作,最大程度上减少了锁的使用,从而接近了 lock free 的效果。
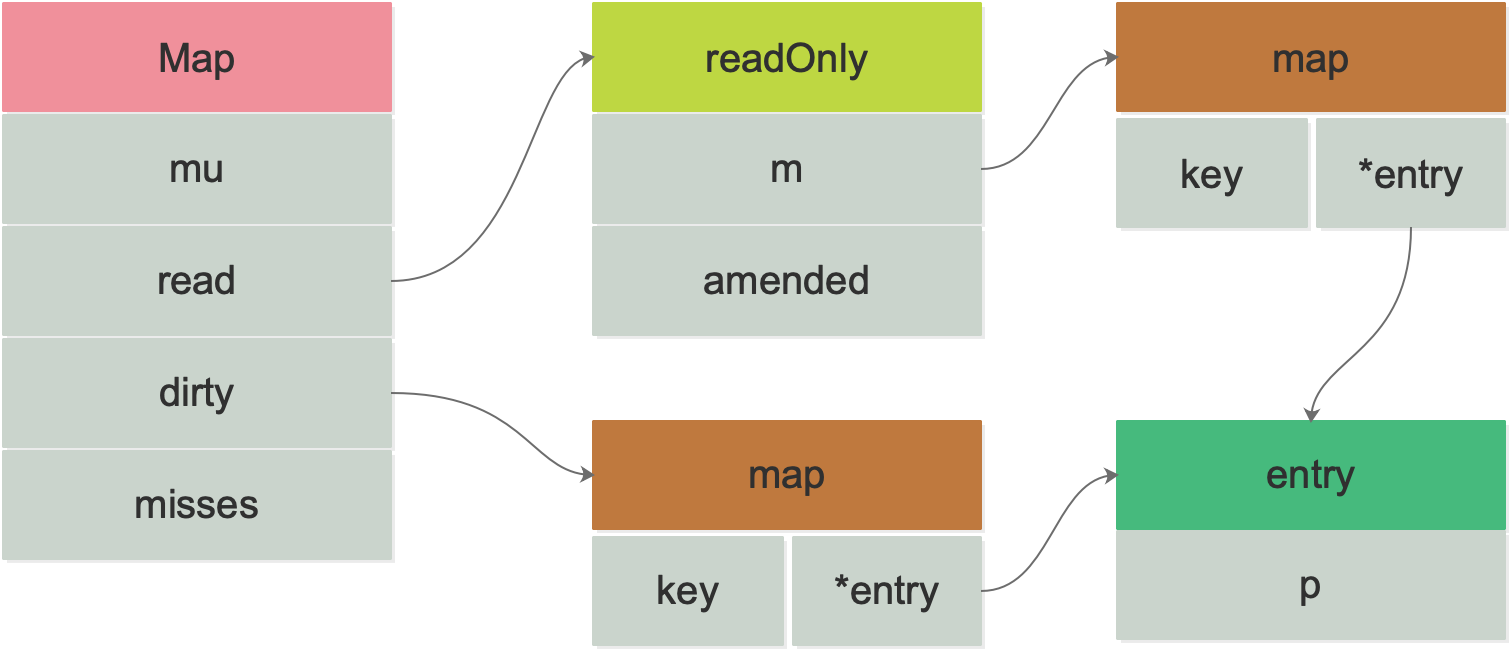
sync.Map 类型的底层数据结构如下👇
type Map struct {
mu Mutex
read atomic.Value // readOnly
dirty map[any]*entry
misses int
}
// Map.read 属性实际存储的是 readOnly。
type readOnly struct {
m map[any]*entry
amended bool
}-
mu:互斥锁,用于保护 read 和 dirty。
-
read:只读数据,支持并发读取(
atomic.Value)。如果涉及到更新操作,则只需要加锁来保证数据安全。 -
read 实际存储的是 readOnly 结构体,内部也是一个原生 map,amended 属性用于标记 read 和 dirty 的数据是否一致,当 dirty 中存在 read 中不存在的 key 时,amended 为
true。 -
dirty:读写数据,是一个原生 map,也就是非线程安全。操作 dirty 需要加锁来保证数据安全。
-
misses:统计有多少次读取 read 没有命中。每次 read 中读取失败后,misses 的计数值都会加 1。
在 read 和 dirty 中,都有涉及到的结构体:
type entry struct {
p unsafe.Pointer // *any
}其包含一个指针 p, 用于指向用户存储的元素(key)所指向的 value 值。
4 atomic.Value
当需要在 Go 中进行并发安全的值存储和读取时,可以使用 sync/atomic 包中的 atomic.Value 类型。atomic.Value 提供了一种原子操作的方式来存储和读取值,以确保在并发环境下不会出现数据竞争。
以下是关于 atomic.Value 的详细说明:
-
创建
atomic.Value: 要创建一个atomic.Value,可以使用sync/atomic包中的atomic.Value类型的零值。例如:var v atomic.Value -
存储值: 使用
Store方法来存储一个值到atomic.Value中。这个操作是原子的,不会出现数据竞争。v.Store("Hello, World!") -
读取值: 使用
Load方法来从atomic.Value中读取值。这个操作也是原子的。value := v.Load() -
并发安全:
atomic.Value保证了存储和读取的操作是并发安全的,不需要额外的锁或互斥体。这对于在多个 goroutine 之间共享数据非常有用。 -
值的类型:
atomic.Value可以存储任何类型的值。这意味着它可以用于存储字符串、整数、结构体、切片、接口等任何 Go 类型。 -
注意事项:
-
虽然
atomic.Value提供了并发安全的存储和读取,但它并不适用于复杂的数据结构。如果需要对复杂数据结构进行并发访问和修改,可能需要使用其他同步机制,如互斥锁。 -
当从
atomic.Value中读取值时,需要进行类型断言,以将接口类型转换为实际的值类型。这需要谨慎处理,以确保类型安全。
-
atomic.Value 是 Go 语言中用于并发安全值存储和读取的有用工具。它在简单的值存储和读取场景中非常有用,可以帮助避免数据竞争问题。但在处理复杂数据结构或需要更复杂同步的情况下,可能需要考虑其他并发控制机制。
5 entry 的 p 可能状态

5.1 nil
当删除一个 key 时,如果 read 中存在会把这个 key 的 value 也就是 e.p 标记为 nil。这样在下次查找的时候还会在 read 中找个这个 key,这时需要去判断下 e.p 是否是 nil,如果是 nil 就表示这个 key 是已经删除的。
如果 read 中不存在但是 dirty 中存在,会先从 dirty 中把这个 key 删除,然后把这个 key 对应的 value 也就是 e.p 标记为 nil。
e.p==nil:entry 已经被标记删除,不过此时还未经过read->dirty重塑,此时可能仍然属于 dirty(如果 dirty 非 nil)。
5.2 expunged
当 dirty->read 完成后,又有新 key 写入时,此时 read 中的 amended 为 false,就会调用 dirtyLocked() 方法,此时会发生 read->dirty 的转变,此时会循环 read 数据,将 p 不为 nil 的值写到 dirty 中,如果 p 为 nil 则将 nil 转为 expunged,
func (m *Map) dirtyLocked() {
if m.dirty != nil {
return
}
read, _ := m.read.Load().(readOnly)
m.dirty = make(map[any]*entry, len(read.m))
println("read->dirty 转变")
for k, e := range read.m {
// 把 read 中 value e.p 不是 expunged 的 key,value 转到 dirty 中
// 这里是循环,如果数据量大可能会非常耗时
if !e.tryExpungeLocked() {
m.dirty[k] = e
}
}
}
func (e *entry) tryExpungeLocked() (isExpunged bool) {
p := atomic.LoadPointer(&e.p)
for p == nil {
// 将 e.p 的 nil 转成 expunged
if atomic.CompareAndSwapPointer(&e.p, nil, expunged) {
return true
}
p = atomic.LoadPointer(&e.p)
}
return p == expunged
}在从 read->dirty 的转变中,虽然 read 中还会存在 expunged 的内容(expunged 是 read 独有的),但是不影响 sync.map 的高性能。相反,如果在 Delete 时直接去删除元素,那么就会去加锁操作 dirty,只要涉及到锁,就会影响到性能。
5.3 正常
此时 entry 是一个普通的存在状态,属于 read,如果 dirty 非 nil,也属于 dirty。
6 Store写入过程
先来看 expunged
var expunged = unsafe.Pointer(new(any))expunged 是一个指向任意类型的指针,用来标记从 dirty map 中删除的 entry。
sync.Map 类型的 Store 方法,该方法的作用是新增或更新一个元素。
func (m *Map) Store(key, value any) {
read, _ := m.read.Load().(readOnly)
if e, ok := read.m[key]; ok && e.tryStore(&value) {
return
}
...
}
// tryStore stores a value if the entry has not been expunged.
//
// If the entry is expunged, tryStore returns false and leaves the entry
// unchanged.
func (e *entry) tryStore(i *any) bool {
for {
p := atomic.LoadPointer(&e.p)
if p == expunged {
return false
}
if atomic.CompareAndSwapPointer(&e.p, p, unsafe.Pointer(i)) {
return true
}
}
}调用Load方法检查m.read中是否存在这个元素。若存在,且在 tryStore 时,判断没有被标记为 expunged 删除状态,则尝试存储。
若该元素不存在或在 tryStore 时判断时,已经被标记为删除状态,则继续走到下面流程👇
func (m *Map) Store(key, value any) {
...
m.mu.Lock()
read, _ = m.read.Load().(readOnly)
if e, ok := read.m[key]; ok {
if e.unexpungeLocked() {
// 如果 read map 中存在该 key,但 p == expunged,则说明在 read 中已经被删除了:
// a. 将 p 的状态由中间值 expunged 更改为 nil
// b. dirty map 插入 key
m.dirty[key] = e
}
// 更新 entry.p = value (read map 和 dirty map 指向同一个 entry)
e.storeLocked(&value)
} else if e, ok := m.dirty[key]; ok {
// 如果 read map 中不存在该 key,但 dirty map 中存在该 key,直接写入更新 entry(read map 中仍然没有这个 key)
e.storeLocked(&value)
} else {
// 如果 read map 和 dirty map 中都不存在该 key,则:
// a. 如果 dirty map 为空,则需要创建 dirty map,并从 read map 中拷贝未删除的元素到新创建的 dirty map
// b. 更新 amended 字段,标识 dirty map 中存在 read map 中没有的 key
// c. 将 kv 写入 dirty map 中,read 不变
if !read.amended {
// 到这里就意味着,当前的 key 是第一次被加到 dirty map 中。
// store 之前先判断一下 dirty map 是否为空,如果为空,就把 read map 浅拷贝一次。
m.dirtyLocked()
m.read.Store(readOnly{m: read.m, amended: true})
}
// 写入新 key,在 dirty 中存储 value
m.dirty[key] = newEntry(value)
}
m.mu.Unlock()
}
func (m *Map) dirtyLocked() {
if m.dirty != nil {
return
}
read, _ := m.read.Load().(readOnly)
m.dirty = make(map[any]*entry, len(read.m))
for k, e := range read.m {
if !e.tryExpungeLocked() {
m.dirty[k] = e
}
}
}
func (e *entry) tryExpungeLocked() (isExpunged bool) {
p := atomic.LoadPointer(&e.p)
for p == nil {
// 将已经删除标记为nil的数据标记为 expunged
if atomic.CompareAndSwapPointer(&e.p, nil, expunged) {
return true
}
p = atomic.LoadPointer(&e.p)
}
return p == expunged
}这里使用了双检查的处理,因为在下面的两个语句中,这两行语句并不是一个原子操作。
if !ok && read.amended {
m.mu.Lock()虽然第一句执行的时候条件满足,但是在加锁之前,m.dirty 可能被提升为 m.read,所以加锁后还得再检查一次 m.read,后续的方法中都使用了这个方法。
由于已经走到了 dirty 的流程,因此开头就直接调用了 Lock 方法上互斥锁,保证数据安全,也是凸显性能变差的第一幕。
写入过程的整体流程是👇
- 如果在 read 里能够找到待存储的 key,并且对应的 entry 的 p 值不为 expunged,也就是没被删除时,直接更新对应的 entry 即可。
- 如果第一步没有成功,要么 read 中没有这个 key,要么 key 被标记为删除。则先加锁,再进行后续的操作。
- 再次在 read 中查找是否存在这个 key,也就是 double check 双检查一下,这是 lock-free 编程的常见套路。如果 read 中存在该 key,但
p == expunged,说明m.dirty != nil(m.dirty是被初始化过的)并且m.dirty中不存在该 key 值(因为已经被删除了,dirty 中的删除直接就删除了;read 中的删除,会先标记为 nil,read->dirty重塑时再标记为expunged),此时👇- 将 p 的状态由
expunged更改为nil - dirty map 插入 key。然后,直接更新对应的 value
- 将 p 的状态由
- 如果 read 中没有此 key,那就查看 dirty 中是否有此 key,如果有,则直接更新对应的 value,这时 read 中还是没有此 key。
- 最后一步,如果 read 和 dirty 中都不存在该 key,则👇
- 如果
dirty为空,则需要创建dirty,并从read中拷贝未被删除的元素 - 更新
amended字段为 true,标识 dirty map 中存在 read map 中没有的key - 将
k-v写入 dirty map 中,read.m不变。最后,更新此 key 对应的value。
- 如果
为什么 read 中存在 key,但是 p == expunged 时需要把 p 的状态由 expunged 更改为 nil ❓
expunged 的意义是在删除操作后,键的对应值被标记为 expunged,而不是简单地设置为 nil。这样做的好处是,nil 值可能是键本身的有效值,因此无法区分键已被删除和键对应的值为 nil 两种情况。通过使用 expunged 标记,sync.Map 可以清楚地区分键被删除和键对应的值为 nil。
if e.unexpungeLocked() {
// The entry was previously expunged, which implies that there is a
// non-nil dirty map and this entry is not in it.
m.dirty[key] = e
}
e.storeLocked(&value)
// storeLocked unconditionally stores a value to the entry.
//
// The entry must be known not to be expunged.
func (e *entry) storeLocked(i *any) {
atomic.StorePointer(&e.p, unsafe.Pointer(i))
}Store 可能会在某种情况下(初始化或者 m.dirty 刚被提升后,此时 m.read 中的数据和 m.dirty 中的相等,readOnly 中的 amended 为 false,也就是说可能存在一个 key,read 中找不到 dirty 中也找不到)从 m.read 中复制数据,如果这个时候 m.read 中数据量非常大,可能会影响性能。
综上,sync.Map 类型不适合写多的场景,读多写少是比较好的。若有大数据量的场景,则需要考虑 read 复制数据时的偶然性能抖动是否能够接受。
7 Load查找过程
sync.Map 类型本质上是有两个 map。一个叫 read、一个叫 dirty,长的也差不多👇
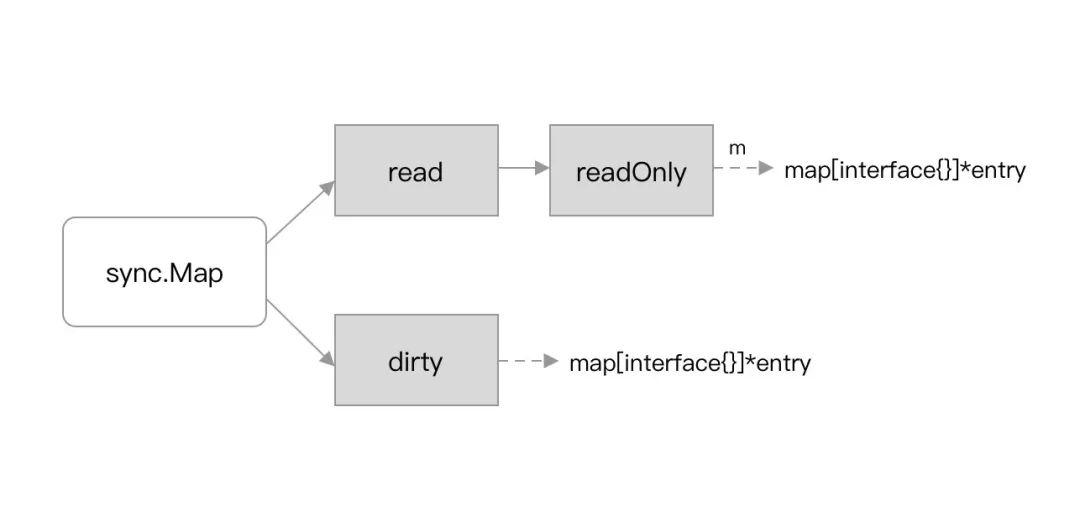
当从 sync.Map 类型中读取数据时,其会先查看 read 中是否包含所需的元素:
- 若有,则通过 atomic 原子操作读取数据并返回。
- 若无,则会判断 read.readOnly 中的 amended 属性,他会告诉程序,dirty 是否包含
read.readOnly.m中没有的数据;如果存在,也就是 amended 为 true,将会进 一步到 dirty 中查找数据。
func (m *Map) Load(key any) (value any, ok bool) {
// 1.首先从 m.read 中得到只读 readOnly,从它的 map 中查找,不需要加锁
read, _ := m.read.Load().(readOnly)
e, ok := read.m[key]
// 2. 如果没找到,并且 m.dirty 中有新数据,需要从 m.dirty 查找,这个时候需要加锁
if !ok && read.amended {
m.mu.Lock()
// 双检查,避免加锁的时候 m.dirty 提升为 m.read,这个时候 m.read 可能被替换了。
read, _ = m.read.Load().(readOnly)
e, ok = read.m[key]
// 如果m.read中还是不存在,并且m.dirty中有新数据
if !ok && read.amended {
// 从m.dirty查找
e, ok = m.dirty[key]
// 不管 m.dirty 中存不存在,都将 misses 计数加一
// missLocked()中满足条件后就会提升 m.dirty
m.missLocked()
}
m.mu.Unlock()
}
if !ok {
return nil, false
}
return e.load()
}处理路径分为 fast path 和 slow path,整体流程如下:
- 首先是 fast path,直接在 read 中找,如果找到了直接调用 entry 的 load 方法,取出其中的值。
- 如果 read 中没有这个 key,且 amended 为 false,说明 dirty 为空,那直接返回空和 false。
- 如果 read 中没有这个 key,且 amended 为 true,说明 dirty 中可能存在我们要找的 key。要先上锁,再尝试去 dirty 中查找。在这之前,仍然有一个 double check 的操作。若还是没有在 read 中找到,那么就从 dirty 中找。不管 dirty 中有没有找到,都要 “记一笔”,因为在 dirty 被提升为 read 之前,都会进入这条路径
那么 m.dirty 是如何被提升的❓ missLocked 方法中可能会将 m.dirty 提升。
func (m *Map) missLocked() {
m.misses++ // 不管在 dirty 中没有读到,miss 都执行 ++ 操作
if m.misses < len(m.dirty) {
return
}
// 如果 miss 的值 >= len(dirty),将 dirty 赋给 read, dirty 和 miss 重新初始化
// 此时 dirty 就为空了,说明从 dirty 全部过渡到了 read, 此时 read 是全量的
m.read.Store(readOnly{m: m.dirty})
m.dirty = nil
m.misses = 0
}直接将 misses 的值加 1,表示一次未命中,如果 misses 值小于 m.dirty 的长度,就直接返回。否则,将 m.dirty 晋升为 read,并清空 dirty,清空 misses 计数值,并且 m.read.amended 为 false。这样,之前一段时间新加入的 key 都会进入到 read 中,从而能够提升 read 的命中率。
再来看下 entry 的 load 方法:
func (e *entry) load() (value any, ok bool) {
p := atomic.LoadPointer(&e.p)
if p == nil || p == expunged {
return nil, false
}
return *(*any)(p), true
}对于 nil 和 expunged 状态的 entry,直接返回 ok=false;否则,将 p 转成 any 返回。
sync.Map 的读操作性能如此之高的原因,就在于存在 read 这一巧妙的设计,其作为一个缓存层,提供了快路径的查找。
8 Delete删除过程
写入过程,理论上和删除不会差太远。怎么 sync.Map 类型的删除的性能似乎还行,那这里面到底是如何实现的呢❓
func (m *Map) Delete(key any) {
read, _ := m.read.Load().(readOnly)
e, ok := read.m[key]
// 如果 read 中没有这个 key,且 dirty map 不为空
if !ok && read.amended {
m.mu.Lock()
read, _ = m.read.Load().(readOnly)
e, ok = read.m[key]
if !ok && read.amended {
delete(m.dirty, key) // 直接从 dirty 中删除这个 key
}
m.mu.Unlock()
}
if ok {
e.delete() // 如果在 read 中找到了这个 key,将 p 置为 nil
}
}第一种情况:可以看到,先从 read 里查是否有这个 key,如果有则执行 e.delete 方法,将 p 置为 nil,这样 read 和 dirty 都能看到这个变化,因为它们指向的是同一块内存地址。
以下是entry.delete方法:
func (e *entry) delete() (hadValue bool) {
for {
p := atomic.LoadPointer(&e.p)
if p == nil || p == expunged {
return false
}
if atomic.CompareAndSwapPointer(&e.p, p, nil) {
return true
}
}
}它真正做的事情是将正常状态(指向一个 any)的 p 设置成 nil。没有设置成 expunged 的原因是,当 p 为 expunged 时,表示它已经不在 dirty 中了,这是 p 的状态决定的,在 tryExpungeLocked 函数中,会将 nil 原子地设置成 expunged。
tryExpungeLocked 是在新创建 dirty 时调用的,会将已被删除的 entry.p 从 nil 改成 expunged,这个 entry 就不会写入 dirty 了。
func (e *entry) tryExpungeLocked() (isExpunged bool) {
p := atomic.LoadPointer(&e.p)
for p == nil {
// 如果原来是 nil,说明原 key 已被删除,则将其转为 expunged。
if atomic.CompareAndSwapPointer(&e.p, nil, expunged) {
return true
}
p = atomic.LoadPointer(&e.p)
}
return p == expunged
}第二种情况:如果没在 read 中找到这个 key,并且 dirty 不为空,那么就要操作 dirty 了,操作之前,还是要先上锁。然后进行 double check,如果仍然没有在 read 里找到此 key,则从 dirty 中删掉这个 key。
注意到如果 key 同时存在于 read 和 dirty 中时,删除只是做了一个标记,将 p 置为 nil;而如果仅在 dirty 中含有这个 key 时,会直接删除这个 key。原因在于,若两者都存在这个 key,仅做标记删除,可以在下次查找这个 key 时,命中 read,提升效率。若只有在 dirty 中存在时,read 起不到 “缓存” 的作用,直接删除。
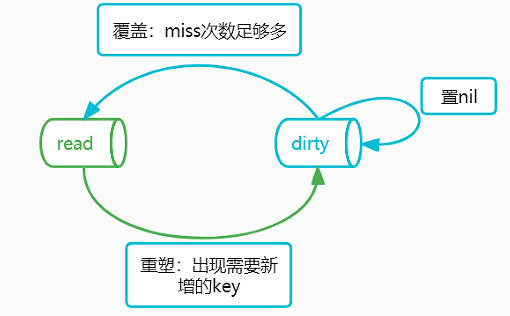
9 dirty和read互转,分别在什么样的时机下进行
-
dirty->read:随着 load 的 miss 不断自增,达到阈值(m.misses >= len(m.dirty))后触发升级转储。 -
read->dirty:当有 read 中不存在的新 key 需要增加,且 read 和 dirty 一致的时候,触发重塑,且read.amended设置为 true,然后再在 dirty 中新增。重塑的过程,会将 nil 状态的 entry,全部转换为 expunged 状态中,同时将非 expunged 的 entry 浅拷贝到 dirty 中,这样可以避免 read 的 key 无限的膨胀(存在大量逻辑删除的 key)。最终,在 dirty 再次升级为 read 的时候,这些逻辑删除的 key 就可以一次性丢弃释放(因为是直接覆盖上去)。
if !read.amended {
// We're adding the first new key to the dirty map.
// Make sure it is allocated and mark the read-only map as incomplete.
m.dirtyLocked()
m.read.Store(readOnly{m: read.m, amended: true})
}
10 read从何而来,存在的意义是什么
-
read 是由 dirty 升级而来,是利用了
atomic.Store一次性覆盖,而不是一点点的 set 操作出来的。所以,read 更像是一个快照,read 中 key 的集合不能被改变(注意,这里说的 read 的 key 不可改变,不代表指定的 key 的 value 不可改变,value 是可以通过原子CAS来进行更改的),所以其中的键的集合有时候可能是不全的。 -
脏字典中的键值对集合总是完全的,但是其中不会包含 expunged 的键值对。
-
read 的存在价值,在于加速读性能(通过原子操作避免了锁)。
11 dirty什么时候是nil
dirty 数据提升为 read 时 m.dirty 会置为 nil。此时,m.read 和 m.dirty 相等,m.amended 为 false,也就是说,read 中找不到的数据,dirty 中同样找不到。
amended bool // true if the dirty map contains some key not in m.func (m *Map) missLocked() {
m.misses++
if m.misses < len(m.dirty) {
return
}
m.read.Store(readOnly{m: m.dirty})
m.dirty = nil
m.misses = 0
}12 删除时 e.p 设置成了 nil 还是 expunged
func (m *Map) Delete(key any) {
m.LoadAndDelete(key)
}
func (m *Map) LoadAndDelete(key any) (value any, loaded bool) {
read, _ := m.read.Load().(readOnly)
e, ok := read.m[key]
// 如果 read 中不存在这个 key 并且 dirty map 中存在这个 key
if !ok && read.amended {
m.mu.Lock()
read, _ = m.read.Load().(readOnly)
e, ok = read.m[key]
if !ok && read.amended {
e, ok = m.dirty[key]
delete(m.dirty, key) // 直接删除 dirty 中的 key,不管 dirty 中存不存在
// Regardless of whether the entry was present, record a miss: this key
// will take the slow path until the dirty map is promoted to the read
// map.
m.missLocked()
}
m.mu.Unlock()
}
// read 中存在或是 dirty 中存在都会走到这里,执行 e.delete()
if ok {
return e.delete()
}
return nil, false
}
func (e *entry) delete() (value any, ok bool) {
for {
p := atomic.LoadPointer(&e.p)
if p == nil || p == expunged {
return nil, false
}
// 把 entry 中的 p 转成 nil,表示已经删除
if atomic.CompareAndSwapPointer(&e.p, p, nil) {
// *(*any)(p) 的作用是将指针 p 指向的数据转换为 any 类型,并且解引用该指针,以便访问 any 类型的值。
return *(*any)(p), true
}
}
}由源码可知,不管 key 是在 read 中还是 dirty 中,最后都调用了 e.delete() 方法,将 e.p 设置为 nil。
13 什么时候 e.p 由 nil 变成 expunged
read->dirty重塑的时候,此时 read 中仍然是 nil 的会变成 expunged,表示这部分 key 等待被最终丢弃(expunged 是最终态,等待被丢弃,除非又出现了重新 Store 的情况)
// 判断 e.p 是不是 expunged, 如果是 e.p 是 nil 则转为 expunged
func (e *entry) tryExpungeLocked() (isExpunged bool) {
p := atomic.LoadPointer(&e.p)
for p == nil {
// 将 e.p 的 nil 转成 expunged
if atomic.CompareAndSwapPointer(&e.p, nil, expunged) {
return true
}
p = atomic.LoadPointer(&e.p)
}
return p == expunged
}- 最终丢弃的时机就是
dirty->read升级的时候,dirty 的直接粗暴覆盖,会使得 read 中的所有成员都被丢弃,包括 expunged。
func (m *Map) missLocked() {
m.misses++ // 不管在 dirty 中没有读到,miss 都执行 ++ 操作
if m.misses < len(m.dirty) {
return
}
// 如果 miss 的值 >= len(dirty),将 dirty 赋给 read, dirty 和 miss 重新初始化
// 此时 dirty 就为空了,说明从 dirty 全部过渡到了 read, 此时 read 是全量的
m.read.Store(readOnly{m: m.dirty})
m.dirty = nil
m.misses = 0
}14 既然 nil 表示标记删除,expunged 的意义是什么
expunged 的意义是在删除操作后,键对应值被标记为 expunged,而不是简单地设置为 nil。这样做的好处是,nil 值可能是键本身的有效值,因此无法区分键已被删除和键对应的值为 nil 两种情况。通过使用 expunged 标记,sync.Map 可以清楚地区分键被删除和键对应的值为 nil。
具体来说,当执行删除操作时,sync.Map 将键对应的值设置为一个特殊的占位符 expunged,表示该键已被删除。在后续的操作中,通过检查值是否等于 expunged,可以判断键是否存在。
这种设计有以下好处:
-
避免了
nil值可能带来的歧义:nil值可能是键的有效值,因此不能简单地依靠nil值来判断键是否存在或已被删除。 -
提高了删除操作的效率:直接将值标记为
expunged,而不是删除键值对,可以避免重新分配内存或进行其他复杂的操作,从而提高了删除操作的效率。 -
保持了并发安全性:通过将键的对应值设置为
expunged,sync.Map在并发环境中仍然能够保持正确的状态和操作一致性。