5.3 awk 命令 #
awk 是一种处理文本文件的语言,是一个强大的文件分析工具。常用于处理 “比较规范” 的文本处理,统计数量并输出指定字段。
awk 比较倾向于将一行分成多个 “字段” 进行处理。awk 信息的读入是逐行读取的,执行结果可以通过 print 将字段数据打印显示。在使用 awk 命令的过程中,可以使用逻辑操作符,&&、|| 、!,还可以进行简单的数学运算,如+、-、*、/、%、^分别表示加、减、乘、除、取余和乘方。
5.3.1 使用格式 #
awk 「选项」 '模式或条件{操作}' 文件名 # 格式1
awk -f 脚本文件 文件名 # 格式2
5.3.2 内置变量 #
| 内置变量 | 功能 |
|---|---|
| NF | 当前处理的行的字段个数(就是:有多少列) |
| NR | 当前处理的行的行号(就是:有多少行) |
| FNR | 读取文件的记录数(行号),从1开始,新的文件重新从1开始计数 |
| $0 | 当前处理的行的整行内容(就是:表示一行的内容) |
| $n | 当前处理行的第n个字段(就是:第n列) |
| FILENAME | 被处理的文件名 |
| FS | 指定每行的字段分隔符,默认为空格或制表位(相当于选项 -F ) |
| OFS | 输出字段的分隔符,默认也是空格 |
| RS | 行分割符。awk 从文件上读取资料时,将根据 RS 的定义把资料切割成许多条记录,而 awk 一次仅读取一条记录,预设值是\n |
| ORS | 输出分割符,默认也是换行符 |
$n 用法 #
n 为数字,数字为几就表示第几列。
- 直接输入全部内容。
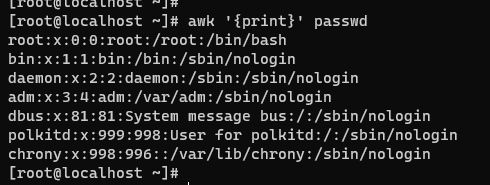
- 要求输出的是第 1 列。但是没有指定分隔符,awk 默认是以空格位分割。所有它认为这整个一行都是一列。

- 设定分割符号
:,输出第 5 列。
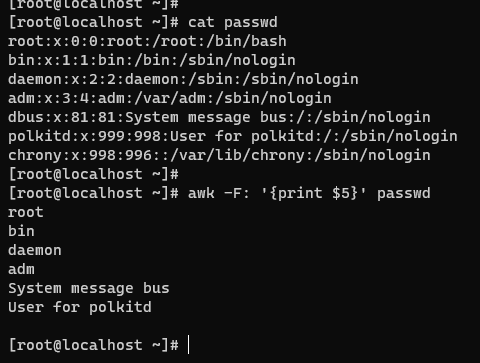
- 设定分割符号
x,输出第 1 列。

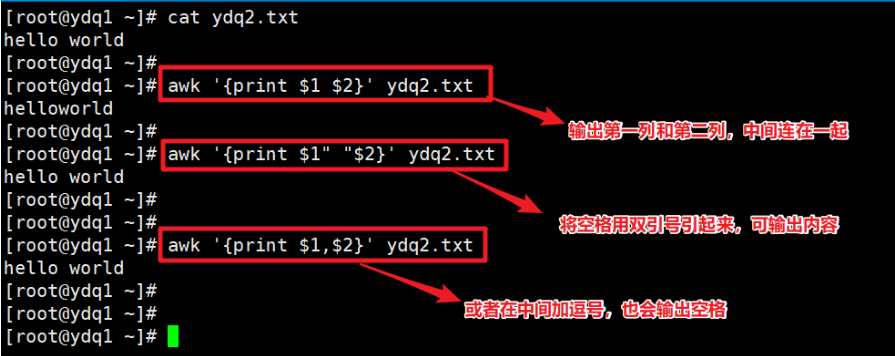
- 输出时,显示列的空格。
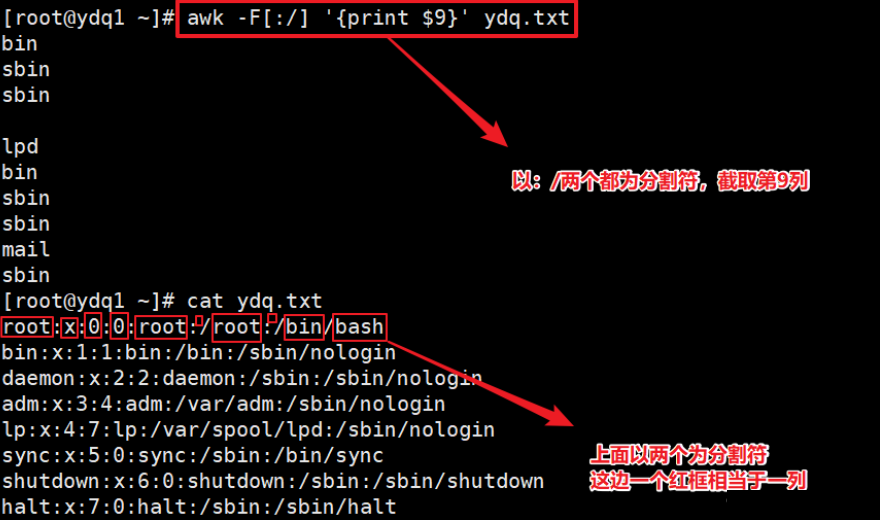
- 设置多个分割符。
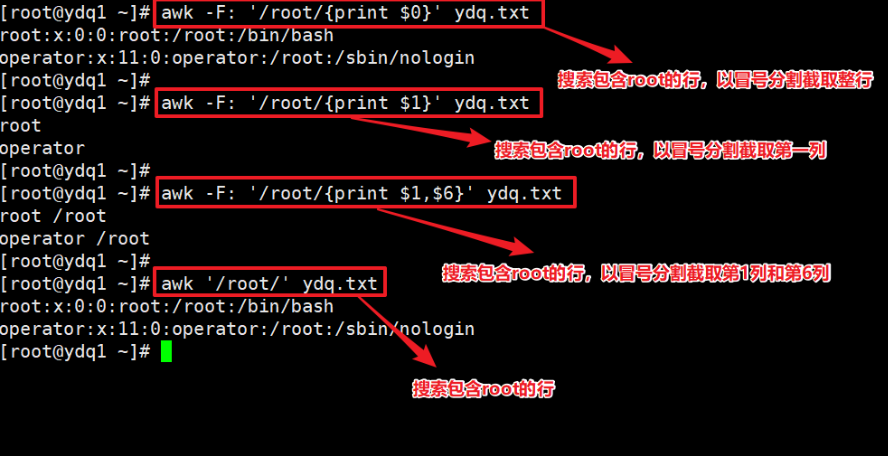
$0 用法 #
$0 表示整行。
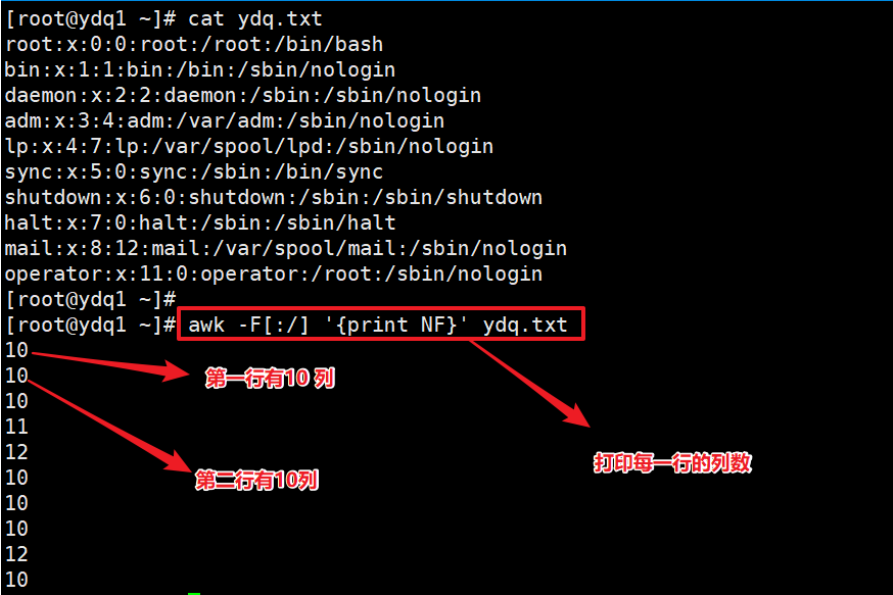
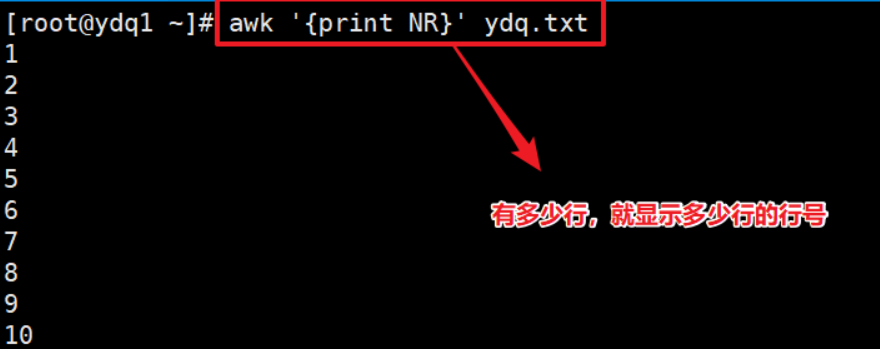
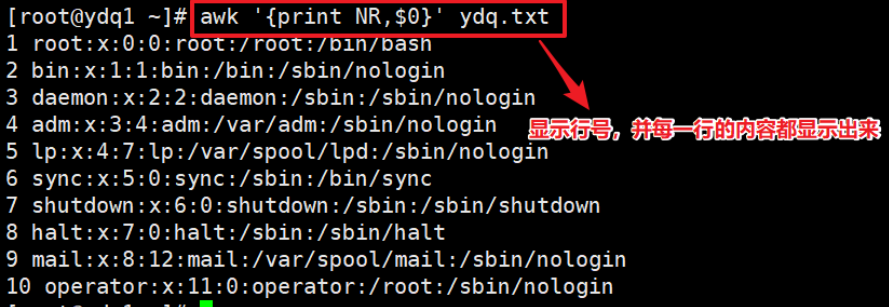
NF 和 NR 用法 #
NF 表示该处理的行序号是多少,表示多少列。NR 表示该处理的行,有多少行。
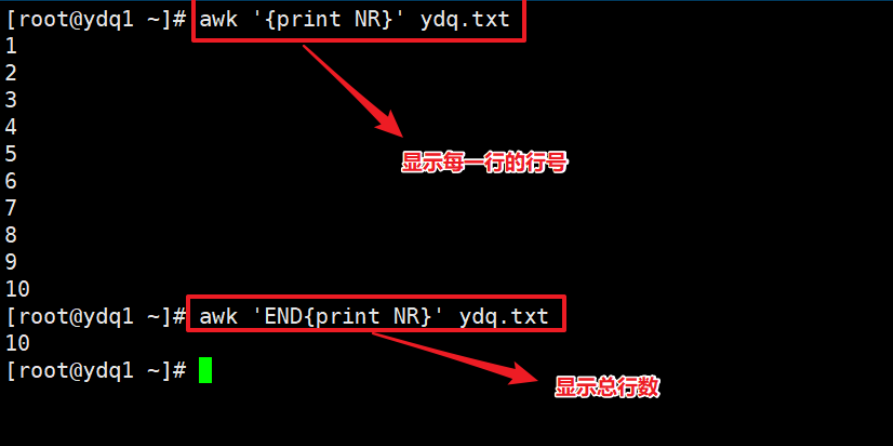
- 打印每一行的列数。
- 显示行号。
- 显示行号,并显示每一行的内容。
- 打印第 2 行,不加 print 也一样,默认就是打印。
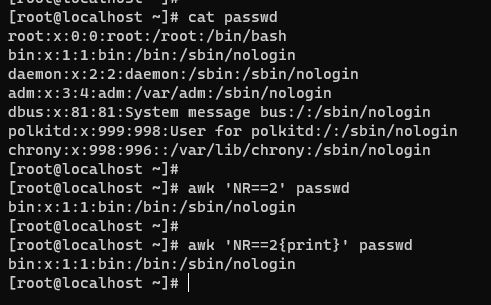
- 打印第 2 行的第 1 列。

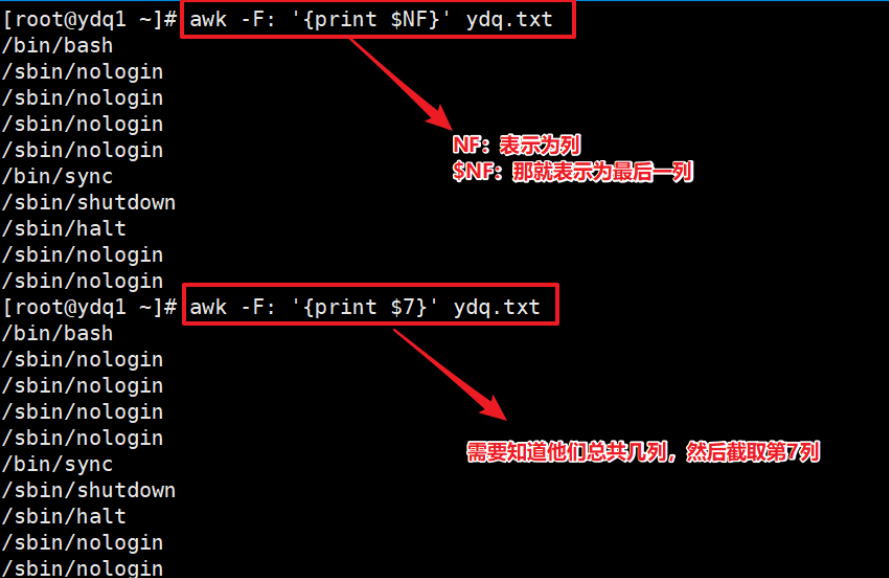
- 打印最后一列。
- 打印总行数。
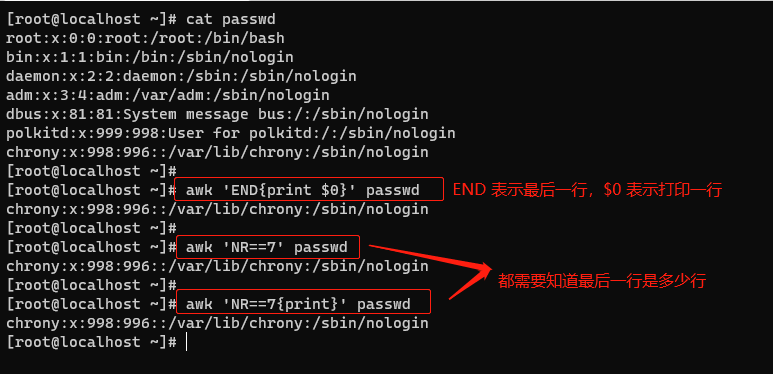
- 打印文件最后一行。
- 加上文字描述行数和列数。

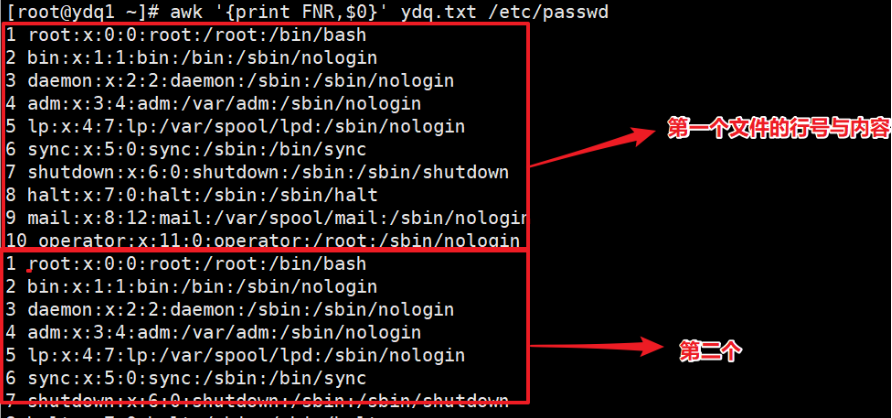
FNR 用法 #
可以看到当有多个文件时,序号会分别标好每一个文件内容的行号,不同文件会从头开始。(NR会连续在一起)。
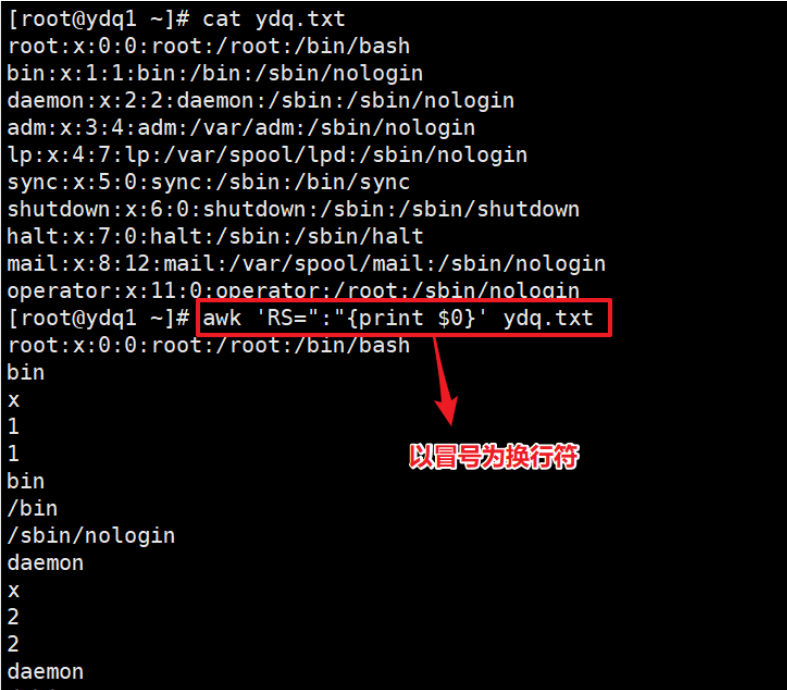
RS 用法 #
指定以什么为换行符,这里指定是冒号,指定的必须是原文里存在的字符。
5.3.3 BEGIN 和 END 用法 #
逐行执行开始之前执行什么任务,结束之后再执行什么任务,用 BEGIN、END。
- BEGIN:一般用来做初始化操作,仅在读取数据记录之前执行一次。
- END:一般用来做汇总操作,仅在读取完数据记录之后执行一次。
常见用法 #
- 在打印之前定义字段分割符为冒号
:。

- OFS 定义了输出时以什么分隔,$1$2 中间要用逗号分隔,因为逗号默认被映射为 OFS 变量,而这个变量默认是空格。

- 把多行合并成一行输出,输出的时候自定义以空格分隔每行,本来默认的是回车键。

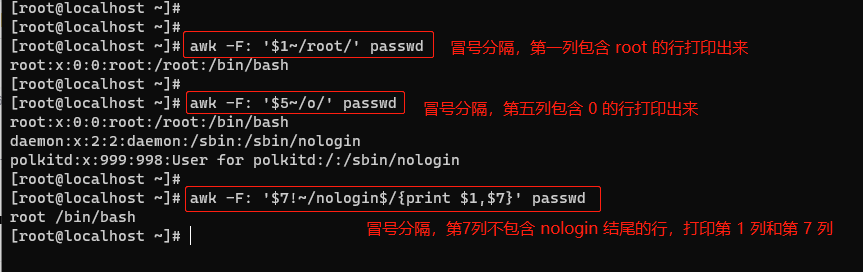
5.3.4 包含与不包含 #
用~表示包含,用!~表示不包含。
5.3.5 数值与字符串比较 #
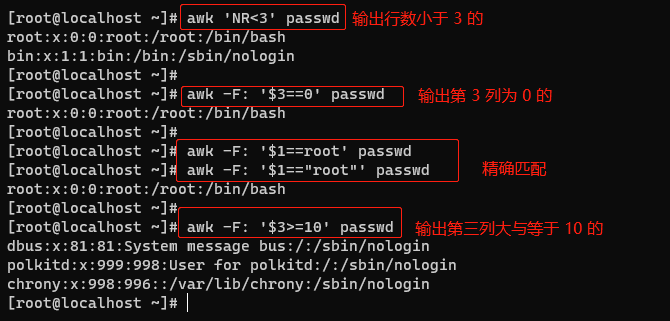
逻辑运算 #
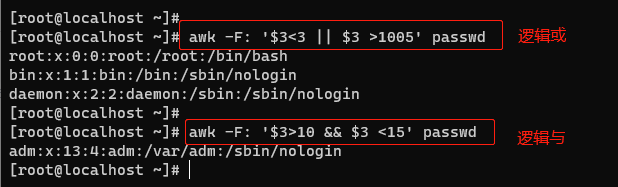
5.3.6 判断和循环 #
现在有个一个 kpi.txt 文档:
user1 70 72 74 76 74 72
user2 80 82 84 82 80 78
user3 60 61 62 63 64 65
user4 90 89 88 87 86 85
user5 45 60 63 62 61 50
判断 #

if 语句后如果跟了多个语句,需要用 {} 括起来。
循环 #
计算一行的总成绩和平均成绩:
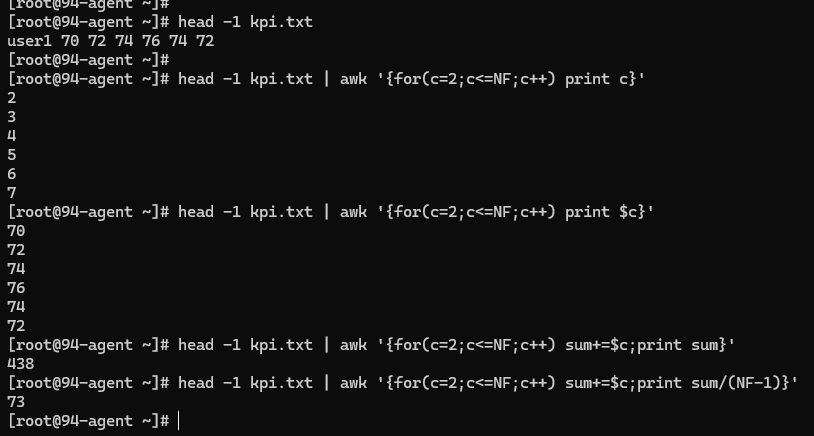
计算每个用户 KPI 平均值:
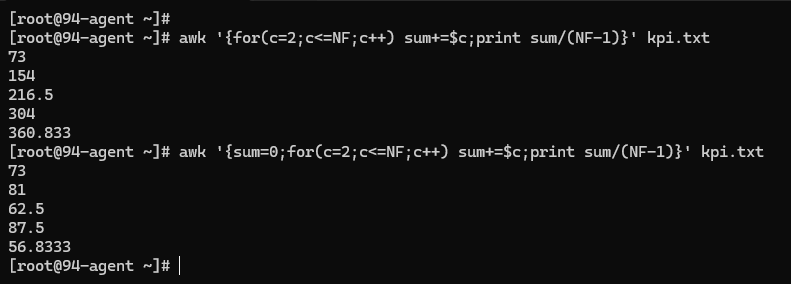
5.3.7 数组 #
定义
数组名\[下标\]=值 下标可以使用数字也可以使用字符串。
遍历
for(变量 in 数组名)
使用数组名[变量] 的方式依次对每个数组的元素进行操作
删除
delete 数组
delete 数组[下标]
# 求每个用户的平均成绩
awk '{sum=0; for(column=2;column <= NF;column++) sum+=$column; average[$1]=sum/(NF-1)} END{ for(user in average) print user,average[user] }' kpi.txt
# 把每个用户的平均成绩相加
awk '{sum=0; for(column=2;column <= NF;column++) sum+=$column; average[$1]=sum/(NF-1)} END{ for(user in average) sum2+=average[user];print sum2 }' kpi.txt
# 总平均成绩的平均成绩
awk '{sum=0; for(column=2;column <= NF;column++) sum+=$column; average[$1]=sum/(NF-1)} END{ for(user in average) sum2+=average[user];print sum2/NR }' kpi.txt
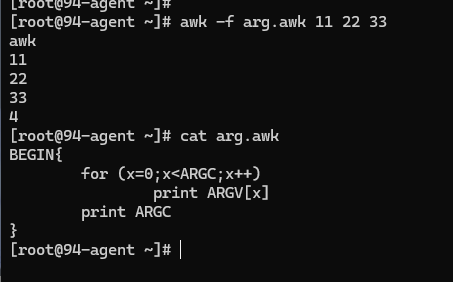
命令行参数数组
在 AWK 编程语言中,ARGC 和 ARGV 是内置变量,用于处理命令行参数。
-
ARGC 是一个整数变量,用于存储命令行参数的数量(包括 AWK 脚本本身)。ARGC 的值表示传递给 AWK 脚本的参数总数。
-
ARGV 是一个字符串数组,用于存储命令行参数的值。ARGV[0] 存储的是 AWK 脚本的名称,而 ARGV[1]、ARGV[2]、ARGV[3],以此类推,存储的是传递给 AWK 脚本的参数值。
综合案例 #
kpi.txt
user1 70 72 74 76 74 72
user2 80 82 84 82 80 78
user3 60 61 62 63 64 65
user4 90 89 88 87 86 85
user5 45 60 63 62 61 50
result.sh
{
sum = 0
for( column = 2; column <= NF; column++ )
sum += $column
average[$1] = sum / (NF - 1)
print "用户",$1,"的平均成绩是:",average[$1]
if (average[$1] >= 80)
letter = "S"
else if(average[$1] >= 70)
letter = "A"
else if (average[$1] >= 60)
letter = "B"
else
letter = "C"
print $1,average[$1],letter
# ----
letter_all[letter]++
}
END {
for( user in average )
sum_all += average[user]
avg_all = sum_all / NR # NR 函数
print "总的平均成绩 avg_all: ", avg_all
for( user in average )
if ( average[user] > avg_all )
above++
else
below++
print "above",above
print "below", below
print "S: ",letter_all["S"]
print "A: ",letter_all["A"]
print "B: ",letter_all["B"]
print "C: ",letter_all["C"]
}

5.3.8 awk 函数 #
算数函数 #
- sin()
- cos()
- int()
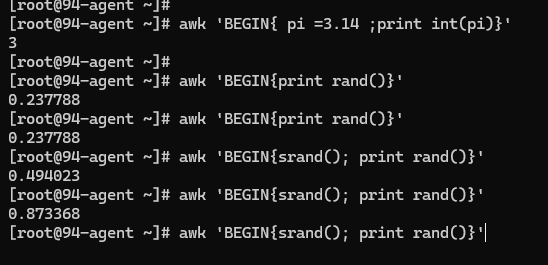
- rand()
- srand()
- …
rand 获取伪随机数,取值范围是 [0,1),需要和 srand() 结合使用,srand() 表示重新获取种子,不然每次 rand() 函数值都是一样的。
字符串函数 #
- gsub(r, s, t)
- index(s, t)
- length(s)
- match(s, r)
- split(s, a, sep)
- sub(r, s, t)
- substr(s, p, n)
- …
自定义函数 #
function函数名(参数){
awk语句
return awk变量
}

5.3.9 常见问题 #
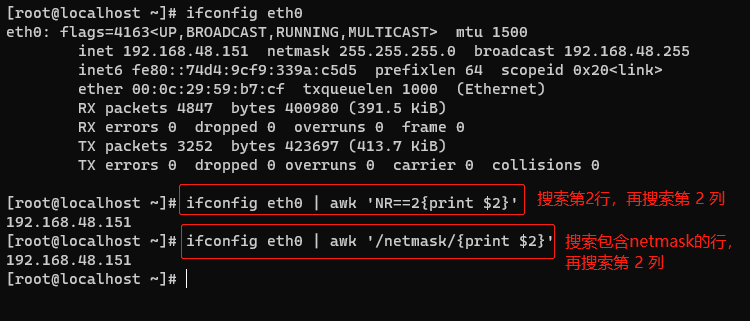
获取本机 ip 地址 #
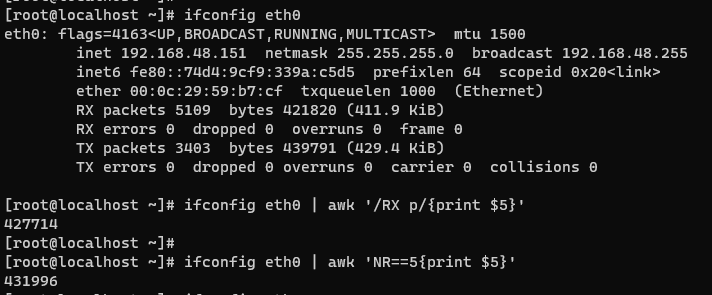
查看本机流量有多少字节 #
查看根分区的可用量 #
5.3.10 总结 #
awk 常用操作是提取转换文本文件内容,awk 功能十分强大,几乎其它文本处理命令能做的,awk 都能做。
- $n 表示截取哪一列,通常和 print 一起使用
- $0 表示整行内容
- NF 表示该行有多少列
- NR 表示该行的行号
- FNR 表示读取两个文件时,序号会分别从0开始标
- FS 表示读取文件的分隔符(默认空格)
- OFS 表示输入的内容以什么为分割符(默认空格)
- RS 表示读取文件的以什么为换行符(默认\n)
- ORS 表示输出的内容以什么为换行符(默认\n)
- ~ 表示包含
- !~ 表示不包含