5.4 cut、sort、uniq、tr 命令 #
5.4.1 cut #
概述 #
cut 是列截取工具。cut 命令从文件的每一行剪切字节、字符和字段并将这些字节、字符和字段写至标准输出。
如果不指定 file 参数,cut 命令将读取标准输入。必须指定 -b(字节) 、-c(字符) 或 -f(第几列) 标志之一。
字符和字节的区别
- 字节(byte)是计量单位,表示数据量多少,是计算机信息技术用于计量存储容量的一种计量单位,通常情况下 1 字节等于 8 位。
- 字符(character)计算机中使用的字母、数字、字和符号。
一般在英文状态下,一个字母或字符占用一个字节, 一个汉字占用两个字节 。
常用选线 #
格式:cut [选项] [文件路径]
| 选项 | 功能 |
|---|---|
| -b | 按字节截取 |
| -c | 按字符截取,常用于中文 |
| -d | 指定以什么为分割符截取,默认为制表符 |
| -f | 通常和 -d 一起使用(表示截取第几列) |
案例演示 #
- 截取 /etc/passwd 文件的中 root 用户的第 7 列(-d -f)

- 按字节截取(-b)
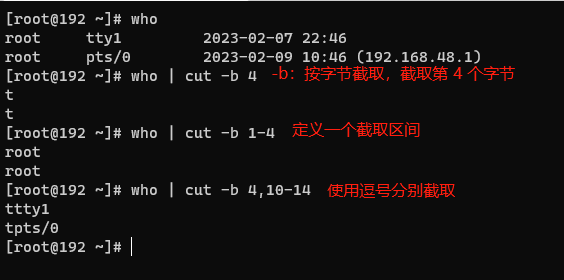
- 按字符截取(-c)
截取第一位是 1,不是 0。

5.4.2 sort #
概述 #
sort 是一个以行为单位对文件内容进行排序的工具,也可以根据不同的数据类型来排序。例如:数据和字符的排序就不一样。
常用选线 #
格式:sort [选项] [文件路径]
| 选项 | 功能 |
|---|---|
| -t | 指定分隔符,默认使用[Tab]键或空格分隔 |
| -k | 指定排序区域,哪个区间排序 |
| -n | 按照数字进行排序,默认是以字母形式排序 |
| -u | 等同于uniq,表示相同的数据仅显示一行,注意:如果行尾有空格就去重就不成功 |
| -r | 反向排序,默认升序 |
| -o | 将排序的结果转存至指定文件 |
案例演示 #
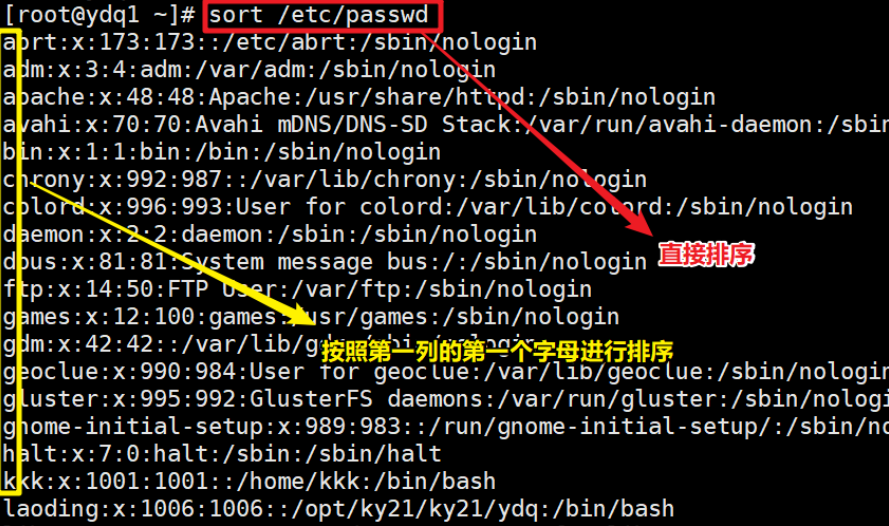
- 不加任何选项,默认按照第一列升序,字母的话就是从 a 到 z
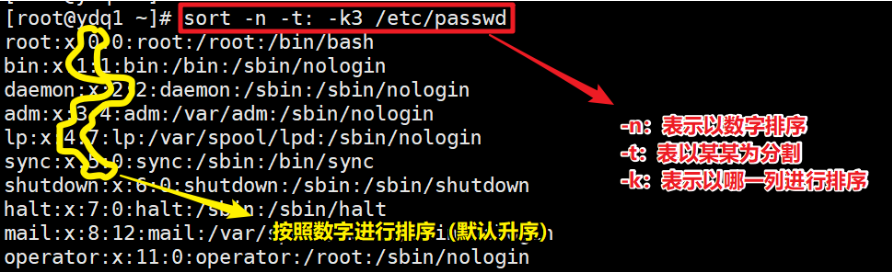
- 指定分隔符(-t),指定排序的列(-k),升序排列
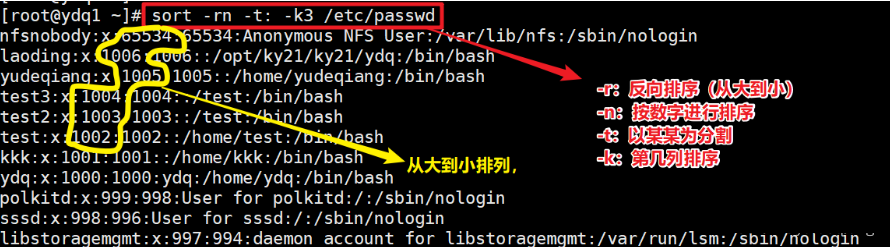
- 指定分隔符,指定排序的列,降序排列(-r)
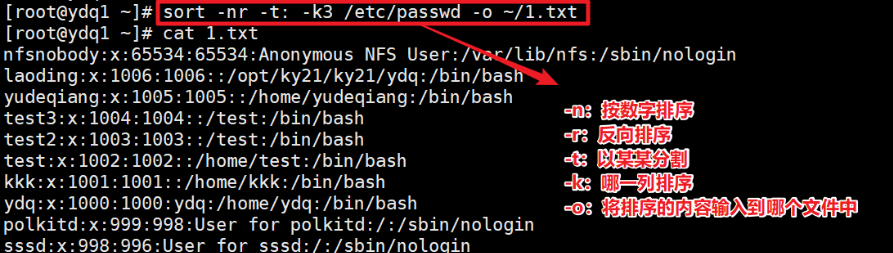
- 指定分隔符,指定排序的列,降序排列,并将排序后的内容输入到/home/ydq/ydq.txt中(-o)
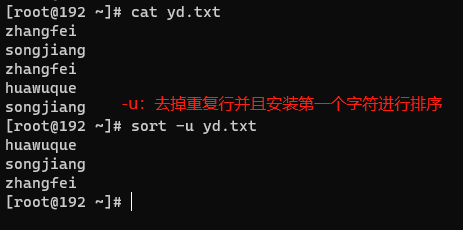
- 去掉文件中重复(可以是不连续的)的行(-u)
5.4.3 uniq #
概述 #
uniq 主要用于去除连续的重复行,注意,是连续的行。通常和 sort 结合使用,先排序使之变成连续的行,再执行去重操作,否则不连续的重复行它不能去重。
常用选线 #
不加选项的话,是直接去掉重复的行。
格式:uniq [选项] 文件路径
| 选项 | 功能 |
|---|---|
| -c | 统计重复的行(在它前面标上重复的次数) |
| -d | 仅显示重复的行 |
| -u | 仅显示出现一次的行(不重复的行) |
案例演示 #
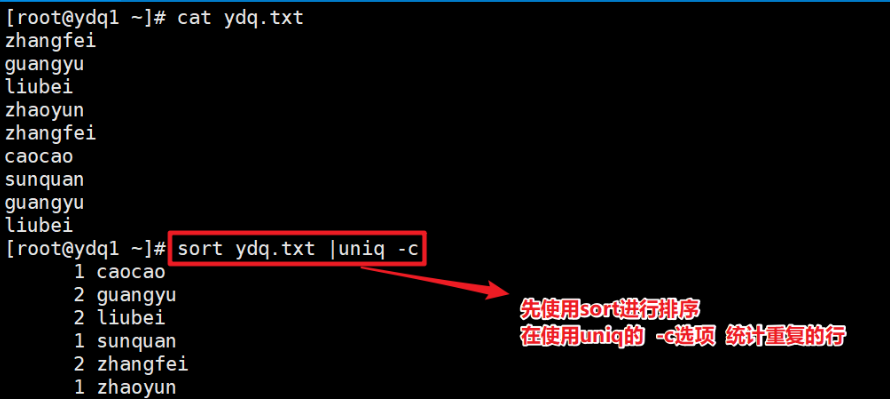
- 统计连续重复的行(-c)
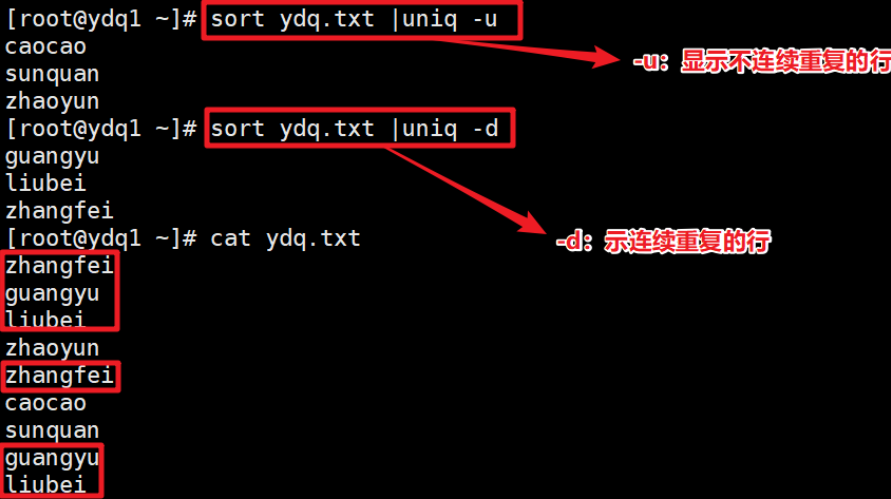
- 显示连续重复的行(-d),显示不连续重复的行(-u)
- 查看当前登录用户,去掉重复的行
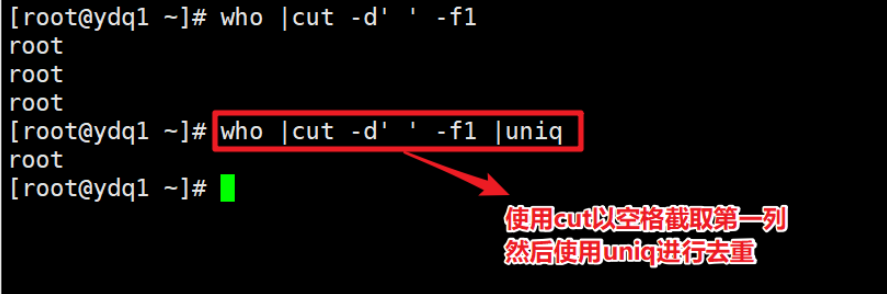
- 统计历史登录过系统的用户

5.4.4 tr #
tr 是修改工具,可以转换或删除文件中的字符。
概述 #
- 可以用一个字符来替换另一个字符
- 可以完全除去一些字符
- 可以用来去掉重复的字符
- 从标准输入中替换,缩减和注释或删除字符,并将结果写到标准输出
常用选线 #
从标准输入中替换、缩减和/或删除字符,并将结果写到标准输出。
格式: tr [选项] '字符集1' '字符集2'
| 选项 | 功能 |
|---|---|
| -d | 删除字符 |
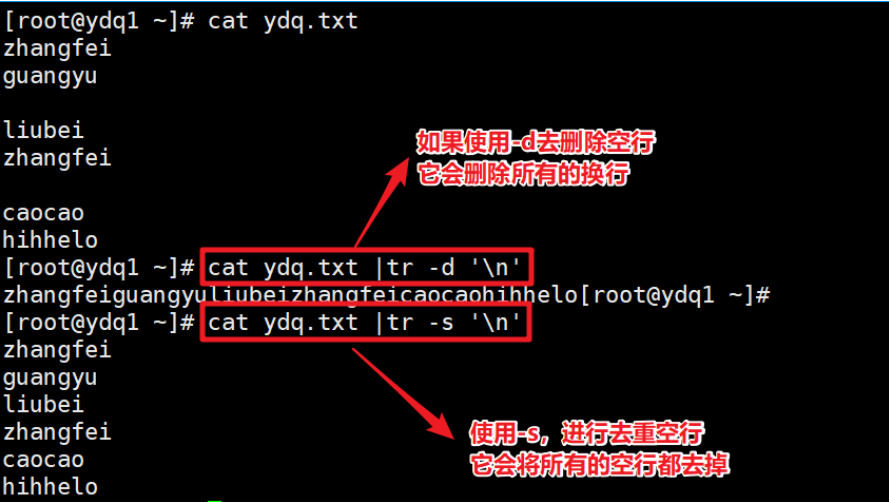
| -s | 删除所有重复出现的字符,只保留一个(如果是空行,全部去掉) |
案例演示 #
- 将所有小写的改成大写
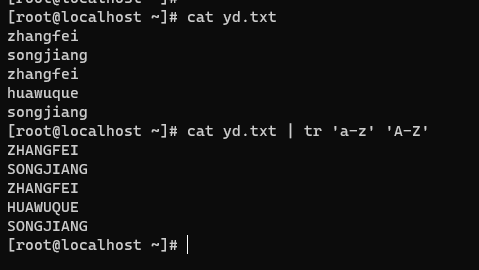
- 替换字母,一一对应替换
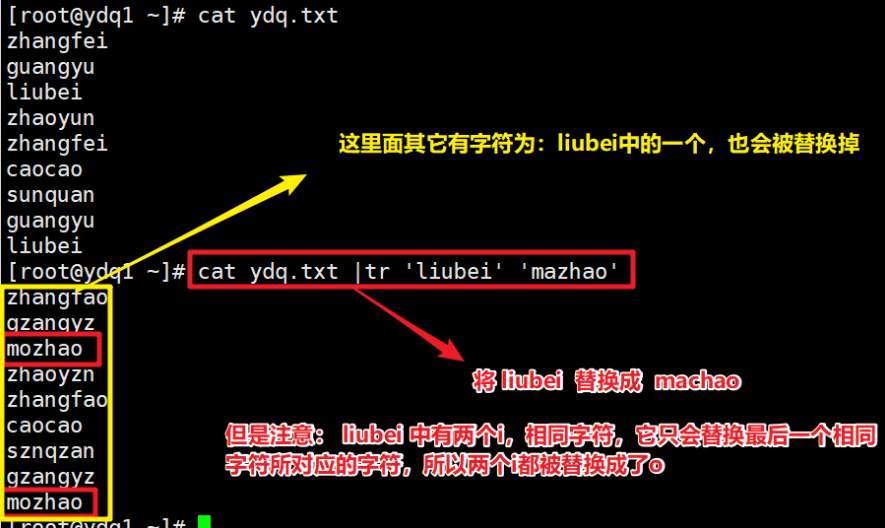
- 替换字符,不是一一对应
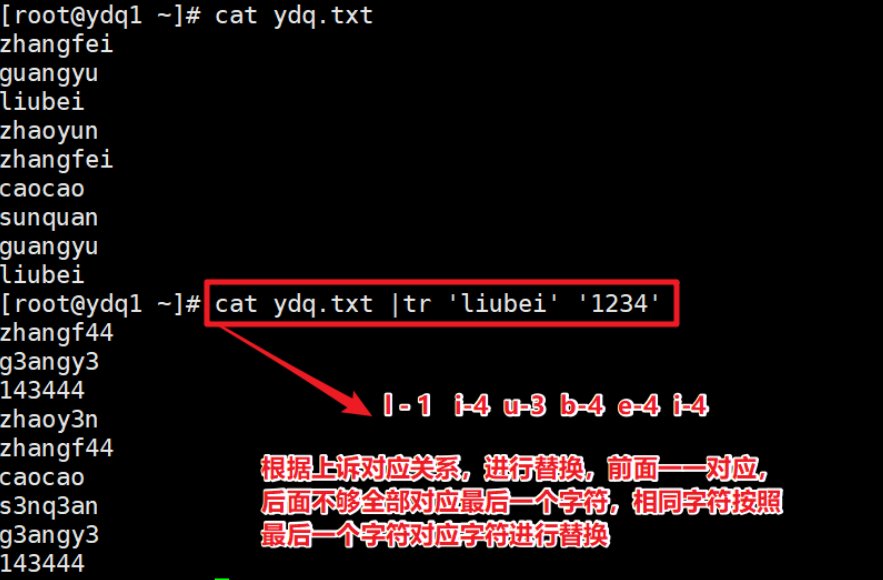
- 将字符替换成特殊字符
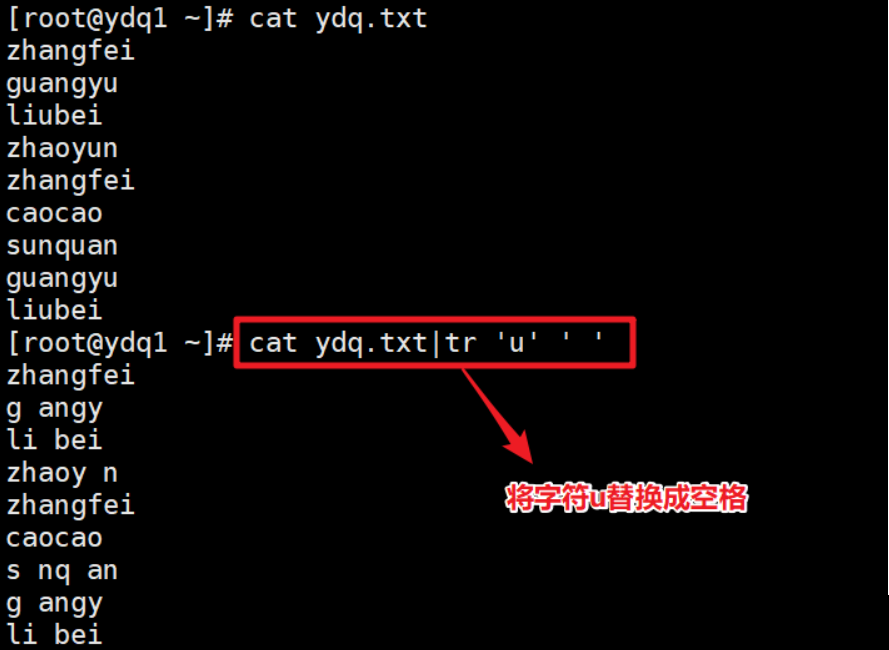
- 删除字符(-d)
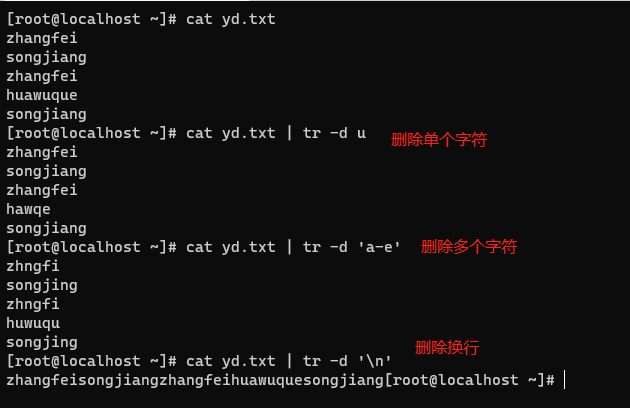
- 对字符去重(-s)
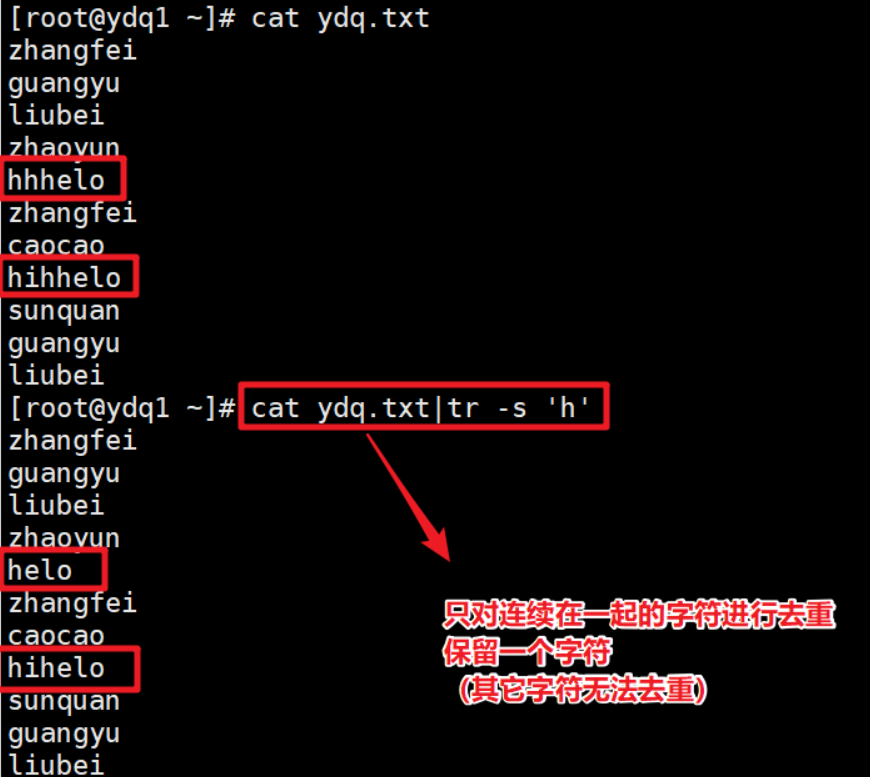
- 去掉所有的空行
5.4.5 面试题 #
1. 统计当前连接主机数 #

2. 统计当前主机的连接状态 #
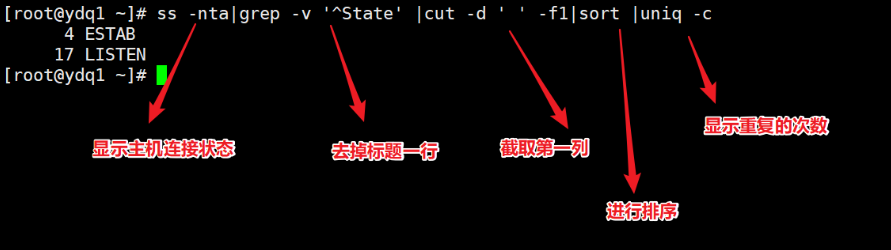
5.4.6 总结 #
cut :表示截取列 #
可以按照字符(-c)按照字节(-b)或者根据分割符(-d)来选取要截取的列(-f)。
sort:表示排序 #
- 默认以字母排序,数字排序需要加选项(-n),反向排序需要加选项(-r)。
- 还可以选择按照哪一列进行排序,需要先定义分割符(-t),然后根据分割符去选取对应的列(-k),最后进行排序。
- 可以将排序后的内容输入到其它文件,使用选项(-o)可以指定需要注入的文件名。
- 还可以将进行去重(-u),可以是不连续的行,进行去重。
uniq:表示去重 #
- 主要注意的是它必须是连续的行,不然无法去重
- 可以根据选项,选择显示不重复的行(-u)
- 还可以选择显示重复的行(-d)
- 还可以统计连续重复的数量(-c)
tr:表示修改字符 #
- 可以修改对应的字符,按照字符对应一一修改,如果有重复的字符,它会按照最后一个字符对应的修改字符进行替换,如果对应的字符不够时,它会将修改的最后一个字符进替换。
- 还可以进行删除(-d),删除文本中所对应的字符
- 还可以进行去重(-s),但是去重的字符必须是连续在一起的两个字符(会保留其中一个),不然无法去重成功。