2.5 Job #
2.5.1 业务分类 #
Kubernetes 里的有两大业务类型。一类是像 Nginx、MySQL 这样长时间运行的 “在线业务”,一旦运行起来基本上不会停,也就是永远在线。另一类是像日志分析这样短时间运行的 “离线业务”,“离线业务” 的特点是必定会退出,不会无期限地运行下去。
“离线业务” 可以分为两种。一种是 “临时任务”,跑完就完事了,下次有需求再重新安排;另一种是 “定时任务”,可以按时按点周期运行,不需要过多干预。在 Kubernetes 里,“临时任务” 是 API 对象 Job,“定时任务” 是 API 对象 CronJob,使用这两个对象就能够在 Kubernetes 里调度管理任意的离线业务。
2.5.2 Job #
比如用 busybox 创建一个 “echo-job”,命令就是这样的:
export out="--dry-run=client -o yaml" # 定义Shell变量
kubectl create job echo-job --image=busybox $out
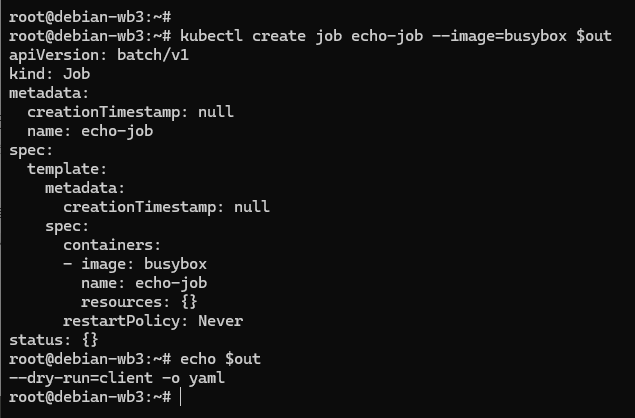
会生成一个基本的 YAML 文件,保存之后做点修改,就有了一个 Job 对象:
apiVersion: batch/v1
kind: Job
metadata:
name: echo-job
spec:
template:
spec:
restartPolicy: OnFailure
containers:
- image: busybox
name: echo-job
imagePullPolicy: IfNotPresent
command: [ "/bin/echo" ]
args: [ "hello", "world" ]
Job 的描述与 Pod 很像,但又有些不一样,主要的区别在 “spec” 字段里多了一个 template 字段,然后又是一个 “spec”,显得很奇怪。这主要是在 Job 对象里应用了组合模式,template 字段定义了一个 “应用模板”,里面嵌入了一个 Pod,这样 Job 就可以从这个模板来创建出 Pod。而这个 Pod 因为受 Job 的管理控制,不直接和 apiserver 打交道,也就没必要重复 apiVersion 等 “头字段”,只需要定义好关键的 spec,描述清楚容器相关的信息就可以了,可以说是一个 “无头” 的 Pod 对象。

apply 创建 Job 对象:
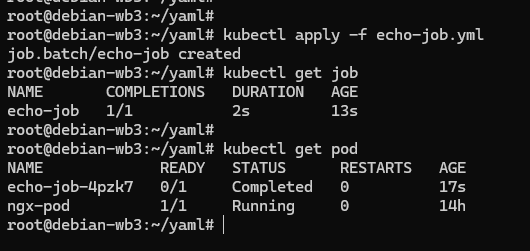
可以看到 Pod 被自动关联了一个名字,用的是 Job 的名字(echo-job)再加上一个随机字符串。
常用字段 #
-
activeDeadlineSeconds,设置 Job 运行的超时时间,单位是秒。该值适用于 Job 的整个生命期,无论 Job 创建了多少个 Pod。 一旦 Job 运行时间达到 activeDeadlineSeconds 秒,其所有运行中的 Pod 都会被终止, 并且 Job 的状态更新为
type: Failed及reason: DeadlineExceeded。 -
backoffLimit,设置 Pod 的失败重试次数。
-
completions,Job 完成需要运行多少个 Pod,默认是 1 个。
-
parallelism,它与 completions 相关,表示允许并发运行的 Pod 数量,避免过多占用资源。
这几个字段并不在 template 字段下,而是在 spec 字段下,它们是属于 Job 级别的,用来控制模板里的 Pod 对象。
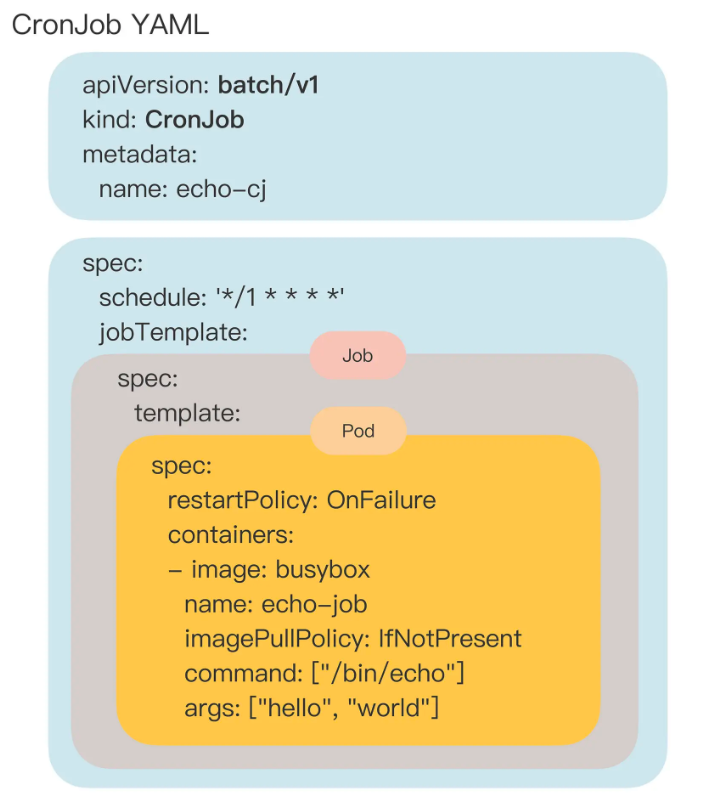
2.5.3 CronJob #
因为 CronJob 需要定时运行,所以在用 create 时需要在命令行里指定参数 --schedule。
export out="--dry-run=client -o yaml" # 定义Shell变量
kubectl create cj echo-cj --image=busybox --schedule="" $out
apiVersion: batch/v1
kind: CronJob
metadata:
name: echo-cj
spec:
schedule: '*/1 * * * *'
jobTemplate:
spec:
template:
spec:
restartPolicy: OnFailure
containers:
- image: busybox
name: echo-cj
imagePullPolicy: IfNotPresent
command: [ "/bin/echo" ]
args: [ "hello", "world" ]
CronJob 有三个 spec 嵌套层次:
-
第一个 spec 是 CronJob 自己的对象规格声明。
-
第二个 spec 从属于 “jobTemplate”,它定义了一个 Job 对象,是必需的。。
-
第三个 spec 从属于 “template”,它定义了 Job 里运行的 Pod。
关于 spec.schedule 的 cron 语法,可以参看 Cron 时间表语法 https://kubernetes.io/zh-cn/docs/concepts/workloads/controllers/cron-jobs/#cron-schedule-syntax。
# ┌───────────── 分钟 (0 - 59)
# │ ┌───────────── 小时 (0 - 23)
# │ │ ┌───────────── 月的某天 (1 - 31)
# │ │ │ ┌───────────── 月份 (1 - 12)
# │ │ │ │ ┌───────────── 周的某天 (0 - 6)(周日到周一;在某些系统上,7 也是星期日)
# │ │ │ │ │ 或者是 sun,mon,tue,web,thu,fri,sat
# │ │ │ │ │
# │ │ │ │ │
# * * * * *
例如0 0 13 * 5表示此任务必须在每个星期五的午夜以及每个月的 13 日的午夜开始。
有一个非常好的网站 crontab.guru 可以很直观地解释 cron 表达式的含义。
2.5.4 其他设置 #
Job 在运行结束后不会立即删除,这是为了方便获取计算结果,但如果积累过多的已完成 Job 也会消耗系统资源,可以使用字段 .spec.ttlSecondsAfterFinished 单位是秒,设置一个保留的时限。
出于节约资源的考虑,CronJob 不会无限地保留已经运行的 Job,它默认只保留 3 个最近的执行结果,但可 以用字段 successfulJobsHistoryLimit 改变。
apiVersion: batch/v1
kind: Job
metadata:
name: my-job
spec:
successfulJobsHistoryLimit: 5
template:
# Job的模板定义
在上面的示例中,successfulJobsHistoryLimit 被设置为5,这意味着只会保留最近 5 个成功的 Job 记录。当成功的 Job 记录超过限制时,最早的记录将被删除。
successfulJobsHistoryLimit 仅适用于成功的 Job 记录。如果要限制失败的 Job 记录数量,可以使用 failedJobsHistoryLimit 参数。