2.9 Deployment #
在线业务远不是单纯启动一个 Pod 这么简单,还有多实例、高可用、版本更新等许多复杂的操作。比如多实例需求,为了提高系统的服务能力,应对突发的流量和压力,需要创建多个应用的副本,还要即时监控它们的状态。如果只使用 Pod,但有人不小心用 kubectl delete 误删了 Pod,又或者 Pod 运行的节点发生了断电故障,那么 Pod 就会在集群里彻底消失,Pod 容器里运行的服务也会消息,这样就会导致业务出现异常。
处理这种问题的思路就是 “单一职责” 和 “对象组合”。既然 Pod 管理不了自己,那么就再创建一个新的对象,由它来管理 Pod,采用 “对象套对象” 的形式。这个用来管理 Pod,实现在线业务应用的新 API 对象,就是 Deployment。
2.9.1 创建 #
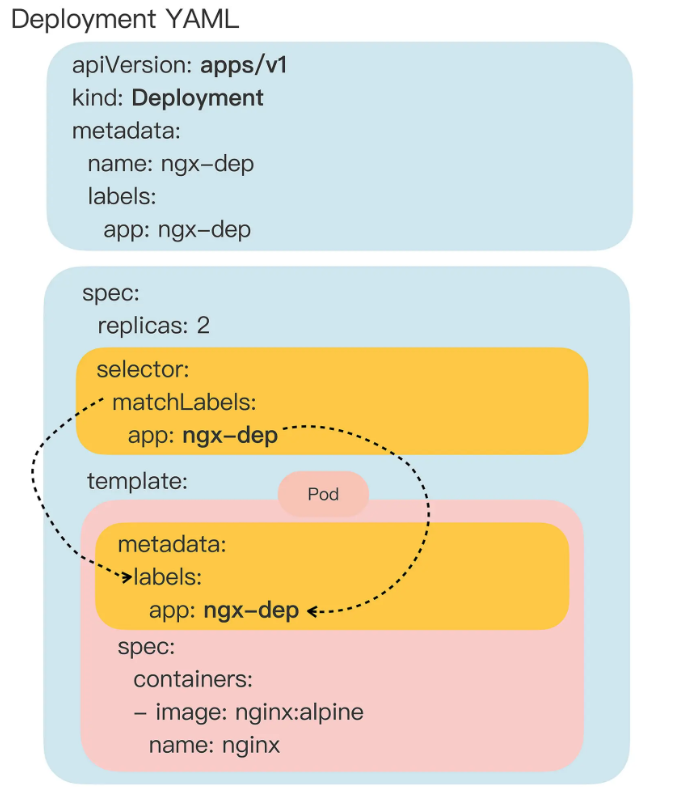
Deployment 的简称是 deploy,它的 apiVersion 是 apps/v1,kind 是 Deployment。
Deployment 的 YAML 描述大致如下:
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: ngx-dep
name: ngx-dep
spec:
replicas: 2
selector:
matchLabels:
app: ngx-dep
template:
metadata:
labels:
app: ngx-dep
spec:
containers:
- image: nginx:alpine
name: nginx
replicas 字段 #
replicas 字段的含义比较简单明了,就是 “副本数量” 的意思,也就是说,指定要在 Kubernetes 集群里运行多少个 Pod 实例。有了这个字段,就相当于为 Kubernetes 明确了应用部署的 “期望状态”,Deployment 对象就可以扮演运维监控人员的角色,自动地在集群里调整 Pod 的数量。
比如,Deployment 对象刚创建出来的时候,Pod 数量肯定是 0,那么它就会根据 YAML 文件里的 Pod 模板,逐个创建出要求数量的 Pod。接下来 Kubernetes 还会持续地监控 Pod 的运行状态,万一有 Pod 发生意外消失了,数量不满足 “期望状态”,它就会通过 apiserver、scheduler 等核心组件去选择新的节点,创建出新的 Pod,直至数量与 “期望状态” 一致。这里面的工作流程复杂,但对于外部用户来说,只需要一个 replicas 字段就可以了,不需要再用人工监控管理,整个过程完全自动化。
selector 字段 #
selector 的作用是 “筛选” 出要被 Deployment 管理的 Pod 对象,下属字段 “matchLabels” 定义了 Pod 对象应该携带的 label,它必须和 “template” 里 Pod 定义的 “labels” 完全相同,否则 Deployment 就会找不到要控制的 Pod 对象,apiserver 也会告诉你 YAML 格式校验错误无法创建。
这个 selector 字段的用法看起来好像是有点多余,但为了保证 Deployment 成功创建,必须在 YAML 里把 label 重复写两次:一次是在 selector.matchLabels,另一次是在 template.matadata。比如上面的例子中就要在这两个地方连续写 app: ngx-dep :
...
spec:
replicas: 2
selector:
matchLabels:
app: ngx-dep
template:
metadata:
labels:
app: ngx-dep
...
Deployment 和 Pod 实际上是一种松散的组合关系,Deployment 实际上并不 “持有” Pod 对象,它只是帮助 Pod 对象能够有足够的副本数量运行,仅此而已。
Kubernetes 采用的是这种 “贴标签” 的方式,通过在 API 对象的 metadata 元信息里加各种标签(labels),就可以使用类似关系数据库里查询语句的方式,筛选出具有特定标识的那些对象。通过标签这种设计,Kubernetes 就解除了 Deployment 和模板里 Pod 的强绑定,把组合关系变成了 “弱引用”。
2.9.2 部署 #
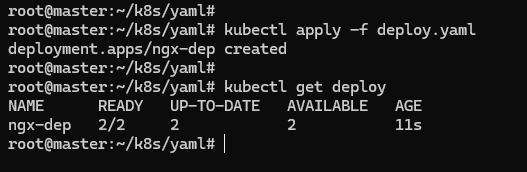
把 Deployment 的 YAML 写好之后,可以用 kubectl apply 来创建对象了:
kubectl apply -f deploy.yml
要查看 Deployment 的状态,可以使用 kubectl get 命令:
kubectl get deploy
-
READY 表示运行的 Pod 数量,前面的数字是当前数量,后面的数字是期望数量,“2/2” 的意思就是要求有两个 Pod 运行,现在已经启动了两个 Pod。
-
UP-TO-DATE 指的是当前已经更新到最新状态的 Pod 数量。因为如果要部署的 Pod 数量很多或者 Pod 启动比较慢,Deployment 完全生效需要一个过程,UP-TO-DATE 就表示现在有多少个 Pod 已经完成了部署,达成了模板里的 “期望状态”。
-
AVAILABLE 要比 READY、UP-TO-DATE 更进一步,不仅要求已经运行,还必须是健康状态,能够正常对外提供服务。
-
AGE 表示 Deployment 从创建到现在所经过的时间,也就是运行的时间。
因为 Deployment 管理的是 Pod,最终使用的也是 Pod,还可以用 kubectl get pod 命令来看看 Pod 的状态:
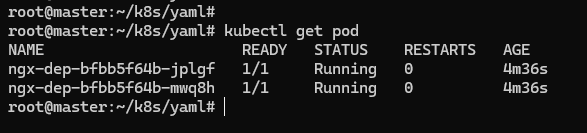
被 Deployment 管理的 Pod 自动带上了名字,命名的规则是 Deployment 的名字加上两串随机数(其实是 Pod 模板的 Hash 值)。
现在可以模拟一下 Pod 发生故障的情景,用 kubectl delete 删除一个 Pod,然后再查看 Pod 的状态:
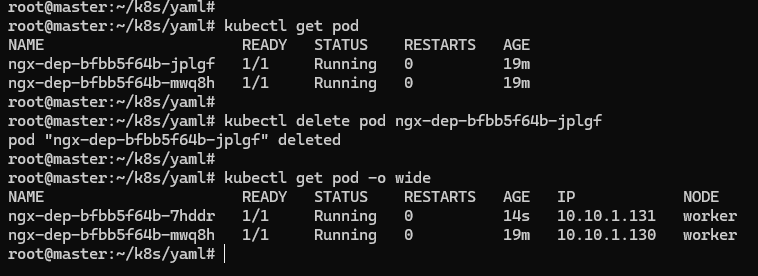
可以看到,被删除的 Pod 确实是消失了,但 Kubernetes 在 Deployment 的管理之下,很快又创建出了一个新的 Pod,保证了应用实例的数量始终是在 YAML 里定义的数量。
2.9.3 扩容伸缩 #
在 Deployment 部署成功之后,可以随时调整 Pod 的数量,实现所谓的 “应用伸缩”。kubectl scale 是专门用于实现 “扩容” 和 “缩容” 的命令,只要用参数 --replicas 指定需要的副本数量,Kubernetes 就会自动增加或者删除 Pod,让最终的 Pod 数量达到 “期望状态”。
比如下面的这条命令,就把 ngx-dep 应用扩容到了 5 个:
kubectl scale --replicas=5 deploy ngx-dep
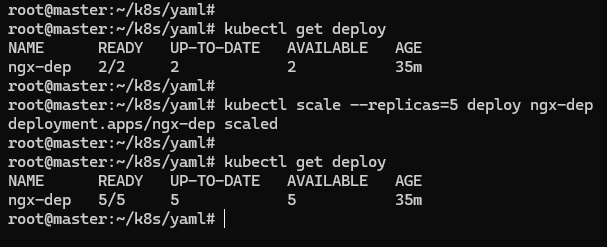
kubectl scale 是命令式操作,扩容和缩容只是临时的措施,如果应用需要长时间保持一个确定的 Pod 数量,还是需要编辑 Deployment 的 YAML 文件,改动 replicas,再以声明式的 kubectl apply 修改对象的状态。
2.9.5 常用命令 #
kubectl get deploy
kubectl get deploy -o wide
kubectl delete deploy xxx
2.9.6 labels 筛选 #
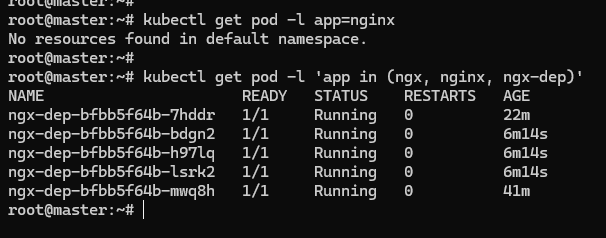
labels 为对象 “贴” 了各种 “标签”,在使用 kubectl get 命令的时候,加上参数 -l,使用 ==、!=、in、notin 的表达式,就能够很容易地用“标签”筛选、过滤出所要查找的对象。
以下两个例子,第一条命令找出 app 标签是 nginx 的所有 Pod,第二条命令找出 app 标签是 ngx、nginx、ngx-dep 的所有 Pod:
kubectl get pod -l app=nginx
kubectl get pod -l 'app in (ngx, nginx, ngx-dep)'